ƒ In November 2018, I reported a number of vulnerabilities in Ghostscript resulting from type confusion. The issues — CVE-2018-19134, CVE-2018-19476 and CVE-2018-19477 — were fixed in Ghostscript version 9.26. In this post, I’ll give some details of how I discovered these vulnerabilities.
Type confusion is a memory-corruption vulnerability that is relatively common in script interpreters such as ChakraCore (the JavaScript engine in Microsoft’s Edge browser) and Ghostscript. It is a powerful type of bug that can be relatively easy to exploit. I’ve written a separate post on how one of these type confusion issues in Ghostscript (CVE-2018-19134) can be turned into a remote code execution vulnerability.
I found these three vulnerabilities using our query technology for variant analysis.
Starting with a series of vulnerabilities that Tavis Ormandy
discovered between 2016 and 2018 (see next section),
I developed a query and ran it over the Ghostscript source code to find variants of those vulnerabilities.
The techniques described in this blog post rely heavily on the CodeQL for Eclipse plugin
to run queries over source code.
You can use the code described in this blog post to query a snapshot of the Ghostscript code.
You can also find the relevant queries and libraries are under the
semmle-security-cpp/(lib|queries)/ghostscript directories in our GitHub repository: https://github.com/Semmle/SecurityQueries.
[EDIT]: You can also use our free CodeQL extension for Visual Studio Code. See installation instructions at https://securitylab.github.com/tools/codeql/.
Type confusions in Ghostscript
Type confusion issues in Ghostscript are not new.
In 2016, Google Project Zero member Tavis Ormandy
reported a number of vulnerabilities in Ghostscript,
one of which is caused by type confusion.
This bug is particularly powerful as it allows you to call an arbitrary function,
provided that the function’s address is known.
Combining it with another
arbitrary-file-read vulnerability that he found,
he was able to read function addresses from /proc/self/maps,
which makes the vulnerability trivially exploitable.
Another (rather infamous) type confusion is “GhostButt”,
which was discovered in 2017 (CVE-2017-8291)
and allegedly exploited in the wild.
This vulnerability can be cleverly exploited to overwrite a variable that controls the sandbox environment
(the LockSafetyParams) to achieve shell command execution.
A good write-up can be found here
(In Chinese, but Google Translate gives you the general idea).
In August 2018, Tavis Ormandy again reported a large number of critical vulnerabilities in Ghostscript, which included three type confusions in the first batch of disclosures.
To understand why type confusion keeps appearing in Ghostscript,
let’s take a look at how PostScript objects are represented in Ghostscript.
PostScript objects in Ghostscript are represented using the struct
ref_s:
struct ref_s {
struct tas_s tas;
union v {/* name the union to keep gdb happy */
ps_int intval;
...
uint64_t dummy; /* force 16-byte ref on 32-bit platforms */
} value;
};
The member tas contains the information of the type,
as well as its accessibility (read-only, write-only, etc.).
The member value is a union which stores the object’s internal data.
This essentially stores an 8-byte integer that gets interpreted either as a pointer or a number,
depending on the type of the object.
It is therefore important to check the actual type of the object before doing anything with the data in value,
otherwise, an integer value may be treated as a pointer and get dereferenced (allowing access to arbitrary memory),
or a pointer value may be treated as an integer (potentially leaking the addresses of arbitrary objects).
In Ghostscript, type checking is done by various macros,
like check_type
and r_has_type.
Types are also checked with switch statements that discriminate according to the type of a ref_s,
as it is done here..
Every PostScript object must be correctly type checked before it is used, but these objects can be very complex.
For or example, you may have a dictionary storing an array that stores a dictionary and so on.
This makes it more difficult to ensure that all objects have been checked correctly; for example:
os_ptr op = osp; //<--- comes from postscript
ref obj1;
ref obj2;
check_type(op, t_dictionary);
code = dict_find_string(op, "field", &obj1); //<--- OK
if (code > 0) {
code = array_get(imemory, obj1, 0, &obj2); //<--- OK, array_get checks type
if (code > 0) {
doSomething(obj2);
}
}
...
int doSomething(ref* obj) {
ref* obj3;
int code = dict_find_string(obj2, "something", &obj3); //<--- What's the type of obj2?!
}
This makes the whole process of type checking very error prone.
Finding type confusions with CodeQL in Ghostscript
Type confusion issues can be modeled as a dataflow problem. After the serious auditing done by Tavis Ormandy and others, any type confusion bugs that are left are probably rather hard for a human to find by hand. So the goal here is to look for type confusions that are buried deep behind a sequence of fetches, like the in example above, as these are less likely to have been discovered.
As with all dataflow problems, let me first identify the source, sink and sanitizer(s).
- The source is an object that comes from a user-controlled PostScript document.
- The sink is an access of
obj->value.xwhereobjis of typeref_sandxis a member in theunionv. - The sanitizer is a type check. However, after a method like
dict_find_stringorarray_get, a new type check is needed.
Conditions 1. and 2. are relatively easy. Condition 3. is more difficult. I’ll now describe how to construct such a query. The resulting code can be found in our GitHub repository.
Dataflow source: The operand stack
Postscript is a stack language, and objects defined in a script are pushed to the operand stack. Ghostscript functions often start like this:
static int zsetcolor(i_ctx_t* i_ctx_p) {
os_ptr op = osp;
...
Here osp is a macro representing i_ctx_p->op_stack.stack.p,
which is the current position in the operand stack.
This gives you an object that comes from the PostScript document you are processing.
The dataflow source that I am interested in is an access to the field p in i_ctx_p->op_stack.stack.
Access to this field can be modeled with CodeQL as follows:
/** An access to an operator stack variable, which are arguments to PostScript functions. */
predicate isOSPAccess(FieldAccess fa) {
exists(FieldAccess opStack, FieldAccess stack |
fa.getTarget().hasName("p")
| fa.getQualifier() = stack and stack.getTarget().hasName("stack") and
stack.getQualifier() = opStack and opStack.getTarget().hasName("op_stack")
)
}
Here the getTarget method gives me the Field of a FieldAccess,
so the above simply says that a FieldAccess fa is an OSP access
if it is a chain of field accesses of the form op_stack.stack.p.
The dataflow source is then:
predicate isOSPSource(DataFlow::Node source) {
exists(FieldAccess fa | isOSPAccess(fa) and source.asExpr() = fa)
}
Dataflow sink: Access to internal data field
The sink here is an access to a field in the union v in the value field of a ref_s type.
First, let’s define a query that finds accesses to the type ref_s,
which takes into account both direct accesses and accesses taken via the address of a variable:
/** Access to a variable of type `ref` or various other equivalent types.*/
class RefAccess extends Expr {
/** The variable of this `ref`*/
Variable v;
RefAccess() {
(v.getAnAccess() = this or v.getAnAccess() = this.(AddressOfExpr).getAnOperand()) and
exists(string name | v.getType().getName() = name |
v.getType() instanceof PointerType or
name = "os_ptr" or name = "const_os_ptr" or
name = "const os_ptr" or name = "ref" or
name = "const ref"
)
}
Variable getVariable() {
result = v
}
/** Convenient predicate to check that two access are to the same variable.*/
predicate isEquivalent(RefAccess other) {
this.getVariable() = other.getVariable()
}
}
I’ve included a method getVariable to help keep track of the variable that gets accessed.
Now let’s define a sink as an expression of the form obj->value.x:
class TypeFieldAccess extends FieldAccess {
TypeFieldAccess() {
exists(FieldAccess f | f.getTarget().hasName("value") and
this.getQualifier() = f and this.getTarget().getDeclaringType().hasName("v")
)
}
RefAccess getRef() {
result = this.getQualifier().(FieldAccess).getQualifier()
}
}
We added a getRef method to keep track of the ref_s object whose internal data is being accessed.
We’ll use this later in our type-check dataflow query.
Type checking sanitizer
Now for the sanitizer.
As explained before, type checking is done by various macros like r_has_type, check_type etc.
Ultimately, these macros use the field type_attrs in the struct tas of ref_s to perform type checking.
So we can consider an expression like obj->tas.type_attrs == some_type as a type check:
/** A comparison statement that is likely to be a type check. */
class TypeCheck extends TypeAttrAccess {
TypeCheck() {
exists(EqualityOperation eq | eq.getAnOperand().getAChild*() = this)
}
}
where TypeAttrAccess is an access to the field type_attrs:
class TypeAttrAccess extends FieldAccess {
TypeAttrAccess() {
exists(FieldAccess fa | fa.getTarget().hasName("tas") and
fa = this.getQualifier() and this.getTarget().getName() = "type_attrs"
)
}
...
}
As mentioned above, another common pattern used for checking type is to use the switch statement, for example:
int
zcopy(i_ctx_t *i_ctx_p)
{
os_ptr op = osp;
int type = r_type(op);
...
switch (type) {
case t_array:
case t_string:
return zcopy_interval(i_ctx_p);
...
}
This can be modeled with CodeQL as:
/** A switch statement that uses the type of a `ref` as the condition. This is a common pattern for checking types. */
class SwitchCheck extends TypeAttrAccess {
SwitchStmt stmt;
SwitchCheck() {
stmt.getControllingExpr().getAChild*() = this
}
SwitchStmt getSwitch() {
result = stmt
}
}
Here, getControllingExpr() of a SwitchStatement gives the switch(type) statement and we are assuming
that if the field access to type_attrs is inside the control statement,
then it probably is a type check. With this in mind, we can now define our sanitizer,
which says that if a DataFlow::Node can only be reached via either a SwitchCheck or a TypeCheck,
then the Node is considered sanitized.
/** A DataFlow::Node that can only be reached after a type check. */
predicate isTypeCheck(DataFlow::Node node) {
exists(TypeAttrAccess tc, RefAccess e | dominates(tc, e) and
e = node.asExpr() and tc.getRef().isEquivalent(e) and
(tc instanceof TypeCheck or tc instanceof SwitchCheck)
)
}
Note that we use the dominates predicate from the standard CodeQL library
to indicate the expression represented by node can only be reached via tc,
which is either a TypeCheck or a SwitchCheck.
The line tc.getRef().isEquivalent(e) ensures that tc is checking the same variable
as the one that is accessed by node.
Adding support to track through collection-fetching methods
Ghostscript has various methods for fetching components inside collection structures such as arrays and dictionaries.
These methods usually pass the input collection as an argument and use an output argument to store the result.
For example, take thearray_get method:
int code = array_get(imemory, arr, 0, &out);
This sets out to the value of the first element of the arr array.
(Note arr is a PostScript array, not a C array — its C type is ref.)
If arr comes from PostScript (tainted), then any access to out should also be tainted.
We can perform tracking of taint through such collections by overriding the isAdditionalFlowStep predicate.
Given that there are various methods like dict_find, dict_find_string,
array_get etc. that we’d like to include, and potentially adding new methods,
it makes sense to first create a base class with CodeQL that captures the essence of these methods:
abstract class FetchMethod extends Function {
abstract int getInput();
abstract int getOutput();
}
Here we define an abstract base class with CodeQL, which has two methods,
getInput and getOutput that will give me the indices
to the input and output arguments in various fetching methods.
Subclasses can override these methods to provide the exact argument index.
For example, for the array_get method:
class ArrayGetMethod extends FetchMethod {
int input;
int output;
ArrayGetMethod() {
this.hasName("array_get") and input = 1 and output = 3
}
override int getInput() {
result = input
}
override int getOutput() {
result = output
}
}
We can now override the isAdditionalFlowStep predicate to find paths
where tainted data can flow from the input argument to the output:
predicate isFetchEdge(DataFlow::Node node1, DataFlow::Node node2) {
exists(FunctionCall fc, FetchMethod f | fc.getTarget() = f |
node1.asExpr() = fc.getArgument(f.getInput()) and
node2.asExpr() = fc.getArgument(f.getOutput()).(RefAccess).getVariable().getAnAccess() and
node1.getEnclosingCallable() = node2.getEnclosingCallable()
)
}
class TypeConfusionConfig extends DataFlow::Configuration {
...
override predicate isAdditionalFlowStep(DataFlow::Node node1, DataFlow::Node node2) {
isFetchEdge(node1, node2)
}
}
The isAdditionalFlowStep predicate tells CodeQL that, if node1 is tainted,
then node2 should be considered tainted if there is a fetch edge from node1 to node2.
When is there a fetch edge from node1 to node2?
Let’s examine the isFetchEdge predicate.
We first specify that node1 is an input argument to a FetchMethod by:
fc.getTarget() = f | node1.asExpr() = fc.getArgument(f.getInput())
The output node is similar, although we taint all accesses to the output variable:
node2.asExpr() = fc.getArgument(f.getOutput()).(RefAccess).getVariable().getAnAccess()
Finally, we restrict this edge to the case where both input and output are
in the same function to avoid some global variable that accidentally got tainted,
which could give a large number of bogus results:
node1.getEnclosingCallable() = node2.getEnclosingCallable()
Counting only the relevant checks
Let’s take a step back and recall the bug pattern we are trying to find:
op -> check -> fetch (dict_find_string etc.) -> use without check
In other words, the initial check is unimportant: we’re interested in scenarios in which a check is not performed after a fetch.
To identify these issues,
we define another dataflow configuration that follows op into any output of a fetch function.
The first dataflow configuration will not care about whether a check is performed or not,
as these checks become irrelevant after a fetch method is called.
It will just give us all outputs of fetch methods that can be reached from op.
We can then use these outputs as the source of another dataflow configuration,
which determines whether a check is missing before the internals of the output are accessed.
The following diagram illustrates how that works:
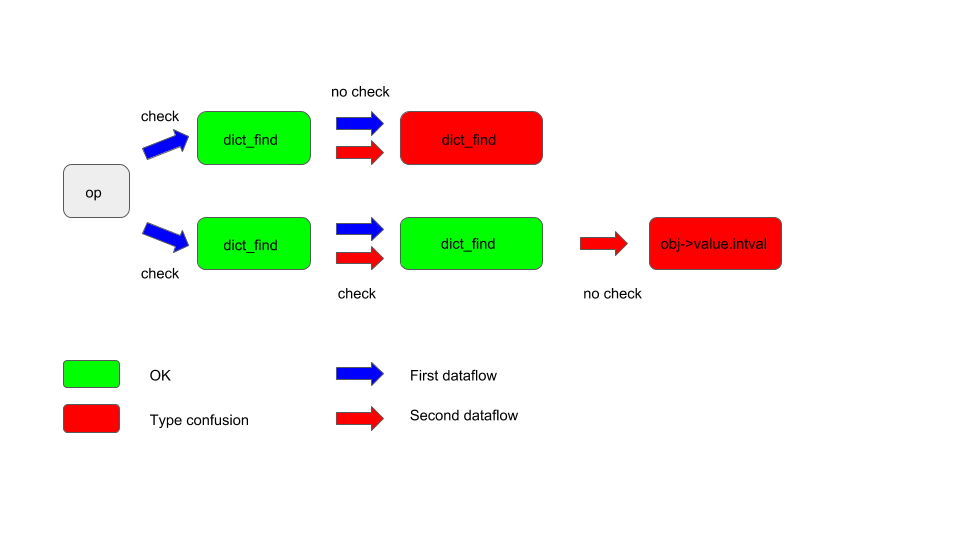
The blue arrows indicate where the first dataflow is tracking and red arrows indicate the second dataflow. Red boxes indicate when a check is missing and a type confusion issue arises. Those are the results we are querying for.
With this in mind, the first dataflow configuration should have:
- The operand stack pointer as source;
- Output of any
FetchMethodas sink; - The ability to follow a
FetchMethodand track from the input collection to the output.
This gives me the following configuration:
class InputSourceConfig extends DataFlow::Configuration {
InputSourceConfig() {
this = "inputSourceConfig"
}
override predicate isSource(DataFlow::Node source) {
isOSPSource(source)
}
override predicate isSink(DataFlow::Node sink) {
exists(FetchMethod f, FunctionCall fc | fc.getTarget() = f |
fc.getArgument(f.getOutput()).(RefAccess).getVariable().getAnAccess() = sink.asExpr()
)
}
override predicate isAdditionalFlowStep(DataFlow::Node node1, DataFlow::Node node2) {
isFetchEdge(node1, node2)
}
}
The second dataflow configuration now starts from the sinks of the first configuration
and ends at a TypeFieldAccess when the internal structure of a ref is accessed.
It should also sanitize against type checking, but should not track across FetchMethod.
class TypeConfusionConfig extends TaintTracking::Configuration2 {
TypeConfusionConfig() {
this = "typeConfusionConfig"
}
override predicate isSource(DataFlow::Node source) {
exists(InputSourceConfig cfg, DataFlow::Node input | cfg.hasFlow(input, source))
}
override predicate isSink(DataFlow::Node sink) {
exists(TypeFieldAccess tc | tc.getRef() = sink.asExpr()
)
}
override predicate isSanitizer(DataFlow::Node node) {
isTypeCheck(node)
}
}
Refining the results
Running the query gives 49 results; that easily allows for manual inspection.
A quick run through the results shows that some of them are not valid because
the TypeFieldAccess is preceded by a function call that also checks its argument type.
For example, one of the results in
zimage3.c
goes into pixel_image_params:
code = data_image_params(imemory, op, (gs_data_image_t *) pim, pip, true, //<--- op from PostScript, not checked
num_components, max_bits_per_component,
has_alpha, islab);
if (code < 0)
return code;
pim->format =
(pip->MultipleDataSources ? gs_image_format_component_planar :
gs_image_format_chunky);
return dict_bool_param(op, "CombineWithColor", false, //<--- dict_bool_param accesses internal data, but OK here
&pim->CombineWithColor); // because data_image_params checks type
This kind of problem is not too difficult to filter out. After taking these type checking functions into account, we arrive at the final query. Running this query against a ghostscript snapshot gives 15 results.
Type confusion results
Let’s take a look at the results. I’ll use the file name in the Resource column to identify these results.
Results in zcolor.c
Some of these are very interesting. In particular, consider the result on line 292:
static int
zsetcolor(i_ctx_t * i_ctx_p)
{
...
if ((n_comps = cs_num_components(pcs)) < 0) {
n_comps = -n_comps;
if (r_has_type(op, t_dictionary)) {
ref *pImpl, pPatInst;
if ((code = dict_find_string(op, "Implementation", &pImpl)) < 0)
return code;
if (code > 0) {
code = array_get(imemory, pImpl, 0, &pPatInst); //<--- Reported by Tavis Ormandy
if (code < 0)
return code;
cc.pattern = r_ptr(&pPatInst, gs_pattern_instance_t); //<--- What's the type of &pPatInst?!
This is especially interesting, because it’s located within 2 lines from another type confusion reported by Tavis Ormandy in August 2018! A minimal PoC that crashes Ghostscript is:
gs -q -sDEVICE=ppmraw -dSAFER
GS><< /Implementation [16#41] >> setpattern
I reported this to the Ghostscript team as bug 700141 and it was assigned CVE-2018-19134.
There’s a second result in zcolor.c which is in fact a piece of duplicate code. That was patched at the same time.
Results in zfjbig2.c
if (r_has_type(op, t_dictionary)) {
check_dict_read(*op);
if ( dict_find_string(op, ".jbig2globalctx", &sop) > 0) {
gref = r_ptr(sop, s_jbig2_global_data_t); //<--- What type is sop?!
s_jbig2decode_set_global_data((stream_state*)&state, gref);
}
}
This one requires the -dJBIG2 flag to be turned on to allow JBig2 decoding. A minimal crashing PoC is:
gs -q -sDEVICE=ppmraw -dSAFER -dJBIG2
GS><</.jbig2globalctx 16#41 >> /JBIG2Decode filter
I reported this as bug 700168 and it was assigned CVE-2018-19477.
Results in zicc.c
I was actually experimenting with a different query when I found another type confusion vulnerability
here,
where type of pnameval was not checked before ->values.bytes was used.
It’s not at all obvious that ICCDict
originates from PostScript. A minimal PoC is:
GS>[/ICCBased <</N 3 /DataSource (abc) /Name 16#41 >>] setcolorspace
I reported this as bug 700169 and it was assigned CVE-2018-19476. The fix also fixed the two results flagged up by my query, so there was no need to report these separately.
Results in zbfont.c
There are quite a few query results in zbfont.c,
although most of them are related to the lack of type checking in the dictionary variable porigfont.
It’s therefore easy to resolve all results with a single small change.
After I reported CVE-2018-19476,
Ken Sharp from Artifex’ Ghostscript team also started adding type checks in various
places.
These checks resolved all results in zbfont.c,
so there was no need to report these.
Although he originally did not intend to port the patch to 9.26 as they were preparing for the release,
I’ve since shown him a minimal PoC that triggered these bugs:
gs -q -dSAFER -sDEVICE=ppmraw
GS>/fontDict 10 dict def
GS>fontDict /FMapType 4 put
GS>fontDict /FDepVector [] put
GS>fontDict /Encoding [] put
GS>fontDict /FontType 0 put
GS>fontDict /FontMatrix matrix put
GS>fontDict /OrigFont 16#41 put
GS>/myFont (myFont) fontDict definefont
Segmentation fault (core dumped)
and:
gs -q -dSAFER -sDEVICE=ppmraw
GS>/fontDict 10 dict def
GS>/fontInfo 2 dict def
GS>/origFont 2 dict def
GS>/origFontName 16#41 def
GS>/origFontStyle 16#41 def
GS>fontDict /FMapType 4 put
GS>fontDict /FDepVector [] put
GS>fontDict /Encoding [] put
GS>fontDict /FontType 0 put
GS>fontDict /FontMatrix matrix put
GS>fontDict /FontInfo fontInfo put
GS>fontInfo /OrigFontName origFontName put
GS>fontInfo /OrigFontStyle origFontStyle put
/myFont (myFont) fontDict definefont def
Segmentation fault (core dumped)
Both of these were patched in Ghostscript 9.26.
The rest of the query results are mostly in code that cannot be reached from -dSAFER,
alongside a single FP in ibnum.c.
Conclusions
In this post I’ve shown how I performed variant analysis on Ghostscript, using our query technology. This effort resulted in the discovery of 6 new type confusions (4 fixed by vendor, 2 reported). What’s more is that the CodeQL library that I built for Ghostscript can now be reused and extended to find other security issues in Ghostscript.
Timeline
- CVE-2018-19134:
- 8 November 2018: Initial private disclosure of the issue to Artifex
- 20 November 2018: Fixed version (9.26) released
- CVE-2018-19476:
- 13 November 2018: Initial private disclosure of the issue to Artifex
- 20 November 2018: Fixed version (9.26) released
- CVE-2018-19477:
- 13 November 2018: Initial private disclosure of the issue to Artifex
- 20 November 2018: Fixed version (9.26) released
[ ]
]