In the first part of this series, I explained some simple tricks that allow us to improve our fuzzing workflow (focusing mainly on AFL/AFL++).
In this second part, I’ll dive deeper into some additional advanced fuzzing concepts.
More than ASAN
The recent progress made in the field of fuzzing has proven to be very relevant for the detection of software vulnerabilities. But when it comes to languages such as C/C++, it would be unfair not to mention the contribution of “Sanitizers” to this success.
Sanitizers (https://github.com/google/sanitizers) are a set of libraries that must be enabled at compile-time, and which allow us to detect vulnerabilities in real-time. Among them, the best known is Address Sanitizer (ASAN).
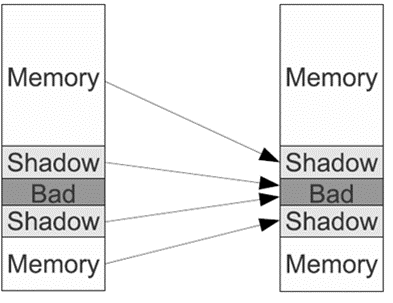
Just to get everyone on the same page, I will briefly review how ASAN works:
- It creates a shadow memory bitmap in which each bit is associated with a byte in real memory
- It then intercepts memory access functions/operations at compile time
- It taints access to variables in adjacent memory locations (e.g. arrays).
To enable ASAN with a compiler like LLVM you only need to add the following compiler option:
-fsanitize=address
While most developers know about the existence of ASAN, many of them still don’t know about other sanitizers such as Undefined Behavior Sanitizer (UBSAN) or Memory Sanitizer (MSAN).
UBSAN is an undefined behavior detector. You can enable UBSAN with -fsanitize=undefined. UBSAN mainly checks:
- Misaligned or null pointers
- Signed integer overflows
- Conversion to, from, or between floating-point types which would overflow the destination.
Due to their potential for higher false positive rates, some UBSAN checks are disabled by default. Among them:
- implicit-conversion: Checks for suspicious behavior of implicit conversions
- integer: Checks for undefined or suspicious integer behavior (e.g. unsigned integer overflow)
- nullability: Checks for nullability violation, e.g. passing null as a function parameter, assigning null to an lvalue, or returning null from a function.
- local-bounds: It can catch cases missed by array-bounds.
We can enable these checks with the following options:
-fsanitize=address,undefined,implicit-conversion,integer,nullability
MSAN is a detector for uninitialized reads. You can enable MSAN with the -fsanitize=memory flag
If you want to disable sanitizer scope for some functions, you can use the no_sanitize attribute before a function definition. This allows us to specify that a particular instrumentation or set of instrumentations should not be applied.
For example:
__attribute__((no_sanitize("integer")))
__attribute__((no_sanitize("implicit-conversion")))
__attribute__((no_sanitize("undefined")))
Moreover, UBSAN doesn’t crash the program when a fail is detected. So we must set abort_on_error=1 if we want AFL to detect UBSAN issues.
Other options that may be interesting to know include:
- check_initialization_order=true, which inserts checks into the compiled program aimed at detecting initialization-order problems
- detect_stack_use_after_return=true, which warns when a variable is used after it has gone out of scope in a function
- strict_string_checks=true, which checks that string arguments are properly null-terminated
- detect_invalid_pointer_pairs=2, which tries to detect operations like
<,<=,>,>=and-on invalid pointer pairs (e.g. when pointers belong to different objects). The bigger the value the harder it tries.
When it comes to fuzzing, ASAN and MSAN are incompatible with each other (unlike UBSAN). To ensure we use the full set of checks available to us, we have to run two sets of executions of the target software:
- Execution 1: ASAN + UBSAN
- Execution 2: MSAN
Since ASAN consumes a lot of virtual memory (about 20TB) you will probably need to use the -m none option in AFL. This option disables memory limits.
Based on the above, a command line example of ASAN enabled fuzzing with AFL could look like:
ASAN_OPTIONS=verbosity=3,detect_leaks=0,abort_on_error=1,symbolize=0,check_initialization_order=true,detect_stack_use_after_return=true,strict_string_checks=true,detect_invalid_pointer_pairs=2 afl-fuzz -t 800 -m none -i ./AFL/afl_in/ -o './AFL/afl_out' -- ./myprogram -n -c @@
In a future post, I will talk about kernel fuzzing and will also cover Kernel Sanitizers: KASAN, KMSAN, and KCSAN.
More than coverage
AFL was undoubtedly one of the greatest recent advances in fuzzing. AFL pioneered coverage-guided fuzzing and quickly became one of the most used tools within the cybersecurity community. This was due to its success in finding real-world vulnerabilities in widely used software while also being very easy to use.
If you’re not familiar with coverage-guided fuzzers, they are a type of fuzzer that make use of code coverage as a feedback mechanism that guides the iterative process of fuzzing. With this approach, the fuzzer can find new execution paths automatically without the user’s assistance.
These types of fuzzers fit into the broader category of feedback-driven fuzzers. This category covers all iterative fuzzers which make use of some kind of feedback mechanism for generating new input cases.
A good example of a feedback-driven fuzzer is FuzzFactory. FuzzFactory defines itself as “an extension of AFL that generalizes coverage-guided fuzzing to domain-specific testing goals”. This explanation might not be the most straightforward, so I’m going to show a few examples that help to clarify on this:
- Maximization of execution paths lengths: In this case, a higher score will be assigned to those inputs that reach deeper execution paths. It’s intended to prioritize those inputs that result in a greater number of executed instructions.
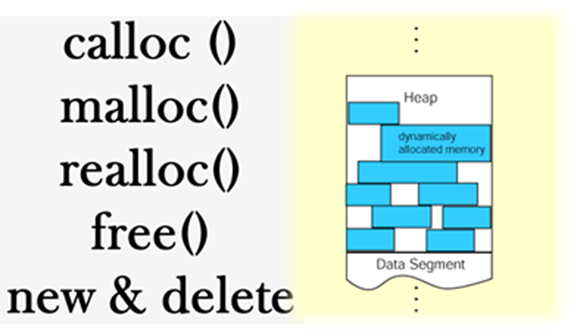
- Inputs that maximize dynamic memory allocations: It’s well known that dynamic memory management is a source of vulnerabilities in memory unsafe languages such as C and C++. That’s why maximizing the number of calls to memory allocations functions (e.g. calloc, malloc, free) is a good strategy to find new bugs.
- Inputs that minimize the number of failed assertions: This aims to avoid the early death of a process when the condition for an assert is not met.
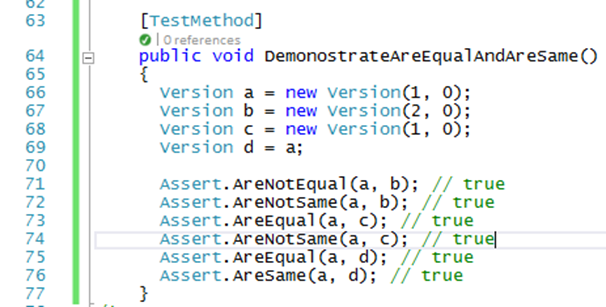
All these examples are not incompatible with coverage-guide fuzzing, in fact quite the opposite. It’s a complementary strategy that we can apply for finding new input cases after we have achieved good code coverage. This will allow us to continue making progress in our fuzzing workflow.
Custom mutators
“Structure-aware-fuzzing” is a bit of a buzzword today in the fuzzing community. As I discussed in my earlier post, it’s possible to use dictionaries to tackle structured code patterns. But that approach is quite poor when facing more complex grammars (e.g. XML). It’s also precisely in these cases where we can get the most benefit from structure-aware fuzzing.
One helpful way to think of structure-aware-fuzzing is as the use of custom mutators. By default, AFL performs simple random mutations such as bit/byte flipping and integer additions or blocks splice/deletion on your input corpus. But through the use of custom-mutators we can introduce our own structure-aware mutations.
For example, we can create custom mutations based on a given grammar:

AFL++ allows the use of custom mutators in two flavors: through a C/C++ API (AFL_CUSTOM_MUTATOR_LIBRARY envvar) or a Python module (AFL_PYTHON_MODULE envvar). I’m going to show a simple example of how to use C/C++ custom mutators:
//Build your target using afl as usual
CC=”afl-clang-fast” ./configure
make
//Now, we build our custom mutator
gcc -shared -Wall -fPIC -O3 my_custom_mutator.c -o my_custom_mutator.so
//We should export the path to the generated .so
export AFL_CUSTOM_MUTATOR_LIBRARY="/home/user/my_custom_mutator.so"
//Now, we can run AFL fuzzer
afl-fuzz -i ‘./AFL/afl_in/’ -o ‘/AFL/afl_out/’ -- ./fuzzTest @@
If everything went well, you will see how the “custom” item (in fuzzing strategy yields) is rising:
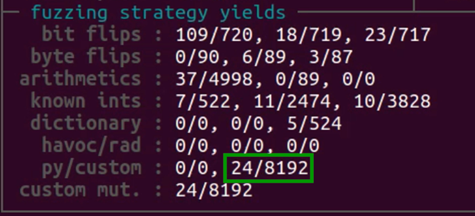
You can find more information about custom mutators in AFL++ at https://github.com/AFLplusplus/AFLplusplus/blob/master/docs/custom_mutators.md
We can also make use of the libprotobuf-mutator library in AFL++. That way, we will able to use .proto files to define our grammar:

Now that we know what structure-aware-fuzzing is, we can ask ourselves when is it useful to use? I’ll try to answer that question based on my own experience.
-
I’ve found the structure-aware fuzzing strategy useful in the following scenarios:
- When you’re fuzzing a software pipeline architecture (note: should not be confused with CPU pipelining). In this case, we refer to a pattern where the output of each element is the input of the next. An example might be a compiler or interpreter, where, if a lexical error occurs, no semantic analysis will be done.
-
When you’re fuzzing a low modularity software, e.g. a software that has a lot of global variables.
-
When you’re dealing with complex restrictions, e.g. web APIs where the request order is decisive. In such cases, if a strict order of input is not followed then execution flow will get stuck in the early stages.
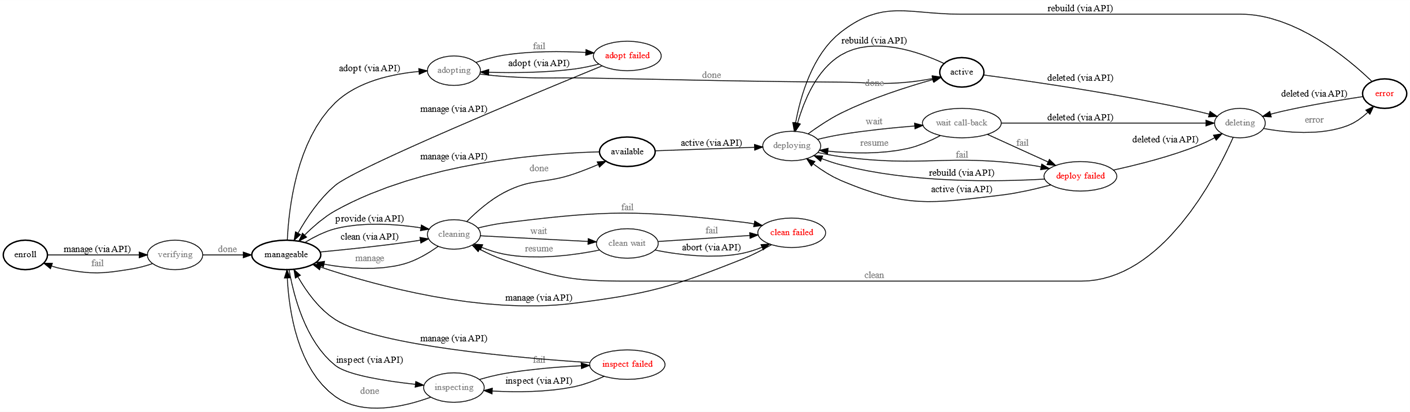
API example (source: https://docs.openstack.org/ironic/pike/contributor/states.html)
-
In contrast, structure aware fuzzing may not be the best option in the following cases:
-
When the software is highly modular: in this case, it would be recommended to fuzz each module separately (see “Custom Coverage” section of this post)
-
When you’re dealing with constant values: use a dictionary instead (see “Providing a custom dictionary” section of this post)
-
When you’re dealing with checksums or CRCs: you should generally just disable CRC in the code (KISS principle) instead of trying to make a fuzzer wrangle its way through the checksum code.
-
There are many other scenarios in which it’s necessary to weigh the advantages and disadvantages of each approach against each other. For example, when the input is ciphered (RC4, AES, etc.) or compressed (RLE, Deflate, etc.).
More than just crashes
It’s commonly believed that fuzzing is a technique that allows us to find memory corruption vulnerabilities, as most of the reported bugs in C/C++ software are of this type. This is because fuzzers such as AFL and LibFuzzer detect fatal signals. These fatal signals are usually the consequence of a crash in our target software.
However, contrary to many people’s beliefs, fuzzing is not limited to memory mismanagement vulnerability detection. It’s also possible to find logical bugs through fuzzing (yes! It’s possible). For this purpose, we need to evolve our fuzzing triage pipeline from “crash monitoring” to “event monitoring.”
I generally take two main approaches to this problem, although I’m sure that there are many other creative ways to achieve the same results.
- Inserting dead barriers: by “dead barriers” I mean points in the code that should not be reachable. For example, I’m going to show an Apache HTTP Server code snippet, where I’ve inserted a dead barrier just after a successful login:
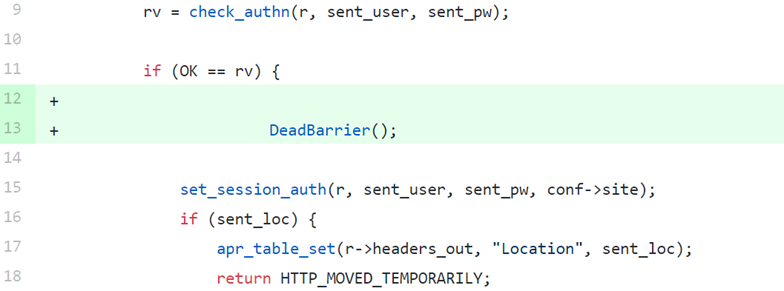
where “DeadBarrier” can be as simple simple as:

By introducing such state barriers I intend to detect if, during the fuzzing process, we have reached any program state that allows us to avoid the Apache authentication flow. Or, in other words, if we have found an “auth bypass” vulnerability. For that, it’s important to set a strong password that won’t be guessed by the fuzzer. The same logic applies to any part of your code that should not be reached, apart from login. This is a powerful technique as it allows you to fuzz for vulnerabilities in program state transitions, AKA logic bugs.
We can also write our own asserts for checking certain conditions that must be met at any stage in the program. Or we could even build a more complex solution, calling an external library to check correctness requirements (a generalization of the ASAN approach).
-
External monitoring: This category includes all the techniques based on external monitoring of fuzzed target outputs, or in other words, the fuzzer will not need to “catch” any event itself, but rather we monitor fuzzer-generated side effects in the target software. Examples include:
-
Output/Logs monitoring: it can be real-time monitoring or “a posteriori” (e.g. using log analytics). A very simple approach could make use of dictionaries or regular expressions to find relevant words or common patterns (similar to how Burp Suite and Zap proxy work). Another more complex alternative could be to use pattern recognition algorithms or neural networks. In both cases, we can make use of external libraries or existing third-party solutions. Good examples of this are ELK Stack and Pattern
-
Monitoring/intercepting system calls: for example, by making use of auditctl or syscall_intercept. We can monitor filesystem read/write events, and detect potential role/privilege manipulation bugs.
-
Conclusion
So far, we have looked at a variety of techniques that will allow us to improve our fuzzing workflow and find more vulnerabilities in real world software. We introduced the concept of fuzzing for logic vulnerabilities and in the coming years we can expect to see many similar advances and out-of-the-box applications of fuzzing methodologies and technology.
Right now, fuzzing is still in its infancy, and in the coming years we will see a lot of progress in this field. But however much fuzzing technology advances, it will always require a spark of human creativity and out of the box thinking to find real-world vulnerabilities.
Need more information?
I’ve used the following resources in this blog post:
- Sanitizers 1 2 3 4
- FuzzFactory
- Libprotobuf Mutator
- AFL++ repository