Powerful, open-source fuzzing tools like AFL and libFuzzer make it easy to find bugs automatically. In some cases it’s as simple as pointing an off-the-shelf fuzzer at some software that hasn’t been fuzzed before and it starts emitting ready-made PoCs which you can attach to GitHub issues. This creates a new burden for volunteer-run open source projects, who now find themselves on the receiving end of a seemingly never-ending stream of security vulnerability reports like these:
Reports like these can be quite demoralizing for the developers on a project. Any bug that’s classified as a security vulnerability immediately takes priority over any other work that’s currently going on. It can disrupt release schedules and create additional administrative burdens such as the need to apply for a CVE and publish a security bulletin. It’s particularly frustrating when the reported vulnerability is extremely low severity. For example, the second issue that I mentioned above could only be triggered in a debug build. Even so, it was assigned CVE-2019-9144, with a HIGH severity rating! In my opinion, that bug wasn’t worth a CVE because it didn’t affect real users (because they would be using a release build, not a debug build). My only guess as to why it was assigned such a scary severity rating is that somebody massively exaggerated their description of its impact when they applied for the CVE.
My goal for this post is to offer some advice to developers on how to escape from the fuzzing police. I believe that they mostly find bugs that are not only relatively simple to find, but also very simple to fix. I’ll demonstrate this with my experience contributing to the Exiv2 project last year. Although AFL found quite a lot of bugs in Exiv2, they were all easy to fix and it didn’t take long to work my way through all of them. I want to encourage developers to run fuzzers on their software and not be scared by the volume of bugs that they appear to find. It’s so much quicker to fix bugs when you find them yourself than when they’re externally reported. In the long run, it saves you a huge amount of time if you’re proactive about finding and fixing them yourself.
How I became an Exiv2 contributor
Last year, I was reviewing some new CodeQL training slides written by my colleagues Luke Cartey and James Fletcher. They used Exiv2 for one of their examples, which piqued my curiosity and prompted me to see if it contained any vulnerabilities. I noticed a handful of low severity issues and reported them to the Exiv2 team, but I found out later that I made the team nervous by posting several new issues in very rapid succession. They thought I was yet another member of the fuzzing police, who was going to dump a bunch of bugs on them and refuse to help fix them. Robin Mills, who was the primary maintainer of Exiv2 at the time, posted a comment on one my issues, asking if I would be willing to help fix the bugs. I was happy to help and Robin and the other developers were very welcoming, especially Luis Díaz Más and Dan Čermák, who ended up reviewing a lot of my pull requests.
After I joined the team and fixed the four issues that I initially reported, I decided to try running AFL on Exiv2 to see if it would find any other issues. I recently reran AFL on commit 55dfdb9 from April 2019, so that I can show you what the carnage looked like at the time. The following image shows one of the AFL status screens after fuzzing on a 16 core Azure VM for three days:
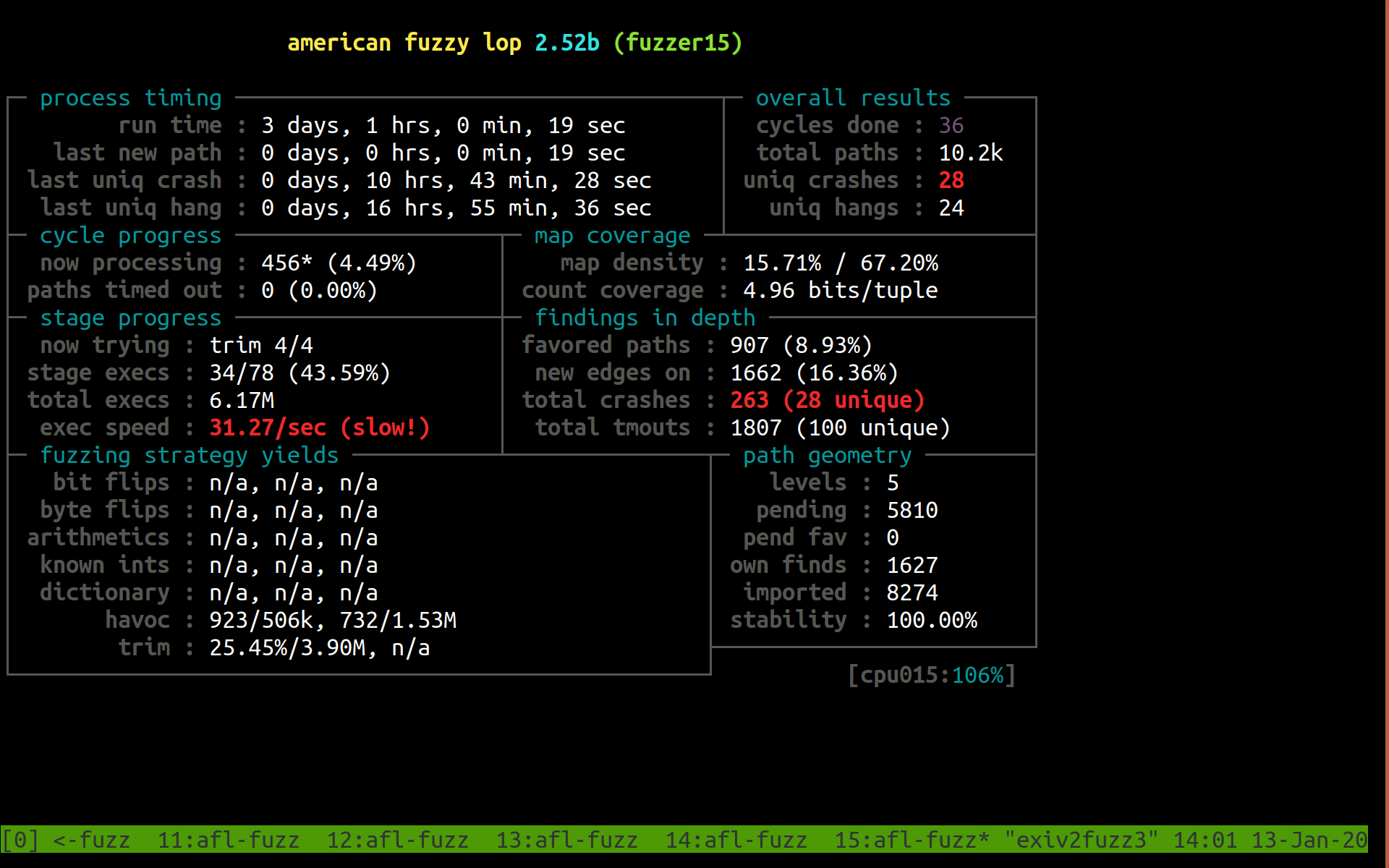
I also recorded a short video, in which I tab through all 16 tmux windows, each of which is running a separate AFL instance, to show that each instance found a significant number of crashes and timeouts.
AFL stores input files that cause a crash in sub-directories named “crashes” and input files that cause a timeout in sub-directories named “hangs”. The following illustrates how many files it created after three days of fuzzing:
kev@exiv2fuzz3:~$ find sync_dir/ -name id:000* | grep crashes | wc -l
374
kev@exiv2fuzz3:~$ find sync_dir/ -name id:000* | grep hangs | wc -l
262
OMG we need to rewrite the whole thing in Rust!
374 bugs!? After only three days of fuzzing! You can understand how results like these can make developers weep, and feel like they need to reach for extreme solutions. One of the most hilarious of these “solutions” is the concept of anti-fuzzing, which aims to thwart the fuzzing police by making fuzzing more computationally expensive. Less ridiculous is the idea that we should stop using C and C++ and instead use memory-safe languages like Rust. But it’s still a huge overreaction to claim that the only way to fix all of those bugs that the fuzzer found is by rewriting the whole project.
The important thing to realize about fuzzers is that they tend to make the situation look a lot worse than it really is, especially if they do not constrain their results to unique crashes only. One bug can look like a thousand if the fuzzer keeps hitting it in different ways. My advice is: don’t panic, just start fixing the bugs and you will quickly get the situation back under control.
374 Fuzzies became 15 easy to fix bugs
Check out the complete list of pull requests that I created to fix the issues. Those 24 pull requests fixed only 15 actual bugs, which shows that the situation wasn’t as bad as it initially seemed.
The bugs were all simple to fix. Almost all of them were caused by missing or incorrect bounds-checks on untrusted data, so the fix was usually a one-liner to insert a bounds-check. Adding a new regression test was often the most time-consuming part of preparing the pull request. As an example, I’ll show you pull request #844, which was one of the more complicated fixes that I implemented, because it took more than a single line of code. The buggy code looked like this:
if (size < 4)
throw Error(kerCorruptedMetadata);
uint32_t o = getULong(pData + size - 4, byteOrder);
if ( o+2 > size )
throw Error(kerCorruptedMetadata);
uint16_t count = getUShort(pData + o, byteOrder);
o += 2;
if ( (o + (count * 10)) > size )
throw Error(kerCorruptedMetadata);
The calls to getULong and getUShort read untrusted values from
the input file,
so we need to be careful to bounds-check those values before
we use them in arithmetic expressions that might
overflow.
In particular, the calculation of o+2 will overflow if
o >= 0xFFFFFFFE.
Similarly, the calculation of o + (count * 10) a few lines later
could overflow if the value of o is large.
I fixed these problems by making a couple of minor tweaks to the code:
if (size < 4)
throw Error(kerCorruptedMetadata);
uint32_t o = getULong(pData + size - 4, byteOrder);
if ( o > size-2 )
throw Error(kerCorruptedMetadata);
uint16_t count = getUShort(pData + o, byteOrder);
o += 2;
if ( static_cast<uint32_t>(count) * 10 > size-o )
throw Error(kerCorruptedMetadata);
The difference is that the code now only does arithmetic
on values that have already been bounds-checked,
so arithmetic overflow is no longer possible.
For example, I replaced o+2 > size with o > size-2,
because we already know that size >= 4
so the calculation of size-2 cannot overflow.
And finally: a quick AFL tutorial
That’s the end of my Exiv2 story, but I want you to go and try fuzzing your own project now. I’ll wrap up the post by showing you how easy it is to fuzz Exiv2 with AFL. Hopefully, you’ll be able to adapt these instructions for your own project. I tested the instructions in this section on Ubuntu 18.04.3 LTS.
First, install AFL and all the packages required to build Exiv2:
sudo apt-get install afl build-essential git clang ccache python3 libxml2-utils cmake python3 libexpat1-dev libz-dev zlib1g-dev libssh-dev libcurl4-openssl-dev libgtest-dev google-mock
Now checkout Exiv2 and build it with afl-clang-fast:
# Checkout
git clone https://github.com/exiv2/exiv2
# Build with afl-clang-fast
mkdir -p exiv2/build_afl
cd exiv2/build_afl
export CC=afl-clang-fast
export CXX=afl-clang-fast++
export AFL_USE_ASAN=1
cmake .. -G "Unix Makefiles"
make -j `nproc`
cd ../..
The effect of AFL_USE_ASAN=1 is to enable the
AddressSanitizer
compiler feature, which helps to find memory corruption bugs.
Now we need to create some initial test cases for AFL to start with. Since the Exiv2 repository already contains a directory full of test cases, we’re able to use those. We just need to discard the larger files, because fuzzing is more effective with smaller files.
mkdir inputs
cp `find ./exiv2/test/data/ -type f -size -4k` inputs/
mkdir sync_dir
And now we’re ready to start AFL:
afl-fuzz -i inputs -o sync_dir -M fuzzer00 -m none -- ./exiv2/build_afl/bin/exiv2 @@
If you want to clobber all your cores then you can start additional AFL instances like this:
afl-fuzz -i inputs -o sync_dir -S fuzzer01 -m none -- ./exiv2/build_afl/bin/exiv2 @@
afl-fuzz -i inputs -o sync_dir -S fuzzer02 -m none -- ./exiv2/build_afl/bin/exiv2 @@
...
And that’s it. Now you wait for the results to start rolling in. Hopefully, you’ll have to wait a very long time if you’re running it on the latest version of Exiv2, but try it on your own project too. Once you’ve fixed everything that you can find with an off-the-shelf fuzzer, try reading my colleague Antonio Morales’s recent blog series to learn more about advanced fuzzing techniques. When you finish that, you should be safe from the fuzzing police for a long time.